| Version 1 (modified by i22balur, 13 months ago) (diff) |
|---|
A veces cuando se muestran las estadísticas de un trabajo de Slurm, se observa como el uso de recursos (cores o memoria) es muy inferior a lo reservado durante parte del trabajo. Esto puede ocurrir por no haber definido un correcto pipeline dentro del trabajo.
En el contexto de HPC (High-Performance Computing), un pipeline es una técnica de procesamiento en la que una serie de tareas o etapas se ejecutan en secuencia. Las etapas del pipeline pueden ser:
- Independientes, lo que permite lanzarlas y ejecutarlas de forma simultánea, siendo lo mejor usar trabajos independientes para cada una de ellas con especificaciones de requerimientos ad hoc para cada uno.
- Dependientes, con lo que se deben ejecutar de forma seriada, debiendo esperar la etapa 2 a que termine la etapa 1, la 3 a la 2, etc.
En el segundo caso, es común que el usuario defina un solo trabajo de Slurm, que lanza un shell script con las tareas puestas de forma secuencial, pero al tratarse de un solo trabajo los requerimientos de memoria y cores se deben ajustar al máximo del conjunto de las tareas.
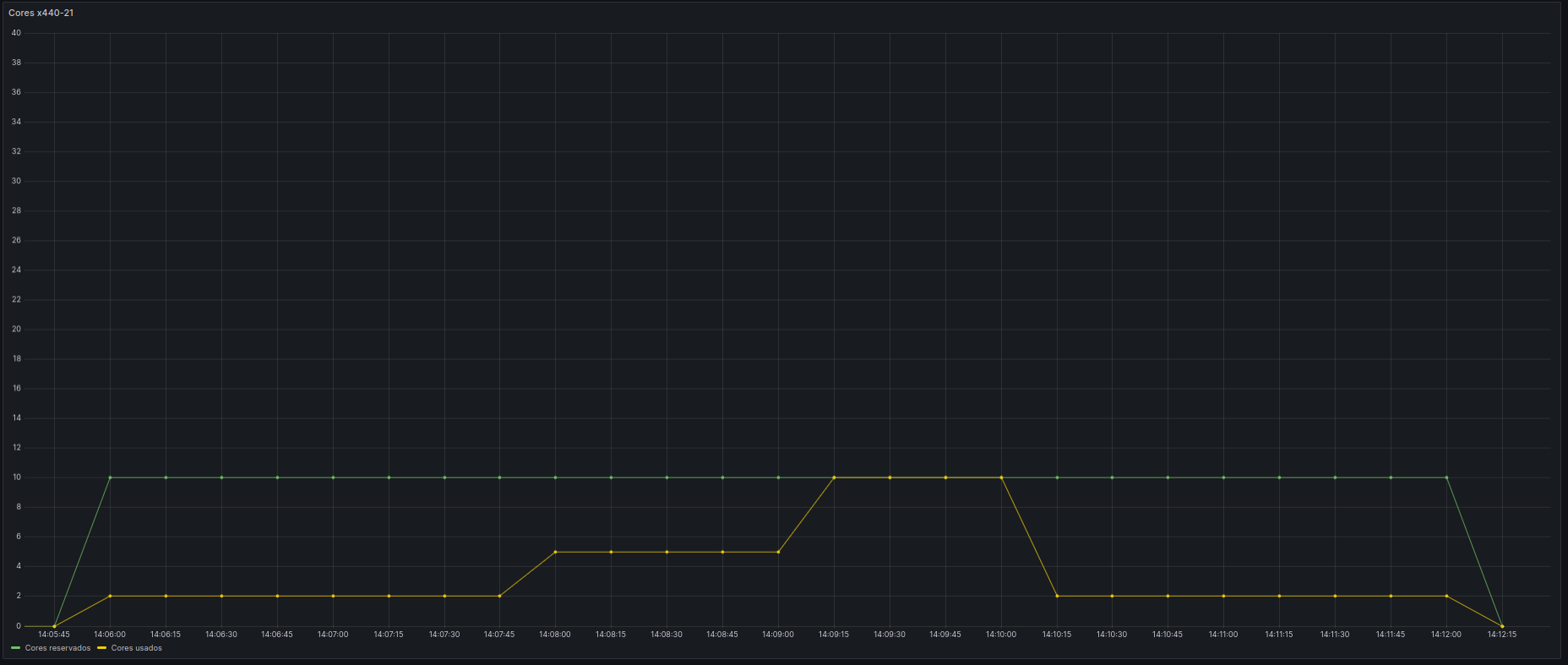
Imagine un pipeline que consiste en los siguientes pasos con los siguientes requerimientos de cores y memoria y su tiempo total de ejecución:
- Adquisición de datos de diferentes orígenes. (1 core, 1Gb, 2 horas)
- "Curado" de los datos (filtrado y preprocesamiento) (4 cores, 10Gb, 1 hora)
- Análisis de los datos (10 cores, 4Gb, 1 hora)
- Generación de resultados (1 core, 1Gb, 2 horas)
Este pipeline tiene 2 pasos (1 y 4) que no son paralelizables y otros dos (2 y 3) que si lo son. Los paralelizables aún cuando tienen más necesidades computacionales, tardan menos al beneficiarse de la ejecución paralela.
El problema es que el pipeline completo tarda 6 horas y si se lanza en un solo trabajo usando las especificaciones de cores y memoria máximos para el conjunto de tareas, se reservarían durante esas 6 horas 10 cores y 10 Gb de memoria, cuando dichas necesidades máximas solo se necesitan en un hora en cada caso.
Esto evidentemente provoca un uso no óptimo de los recursos del HPC, impidiendo que otros trabajos puedan ejecutarse cuando realmente hay recursos ociosos.
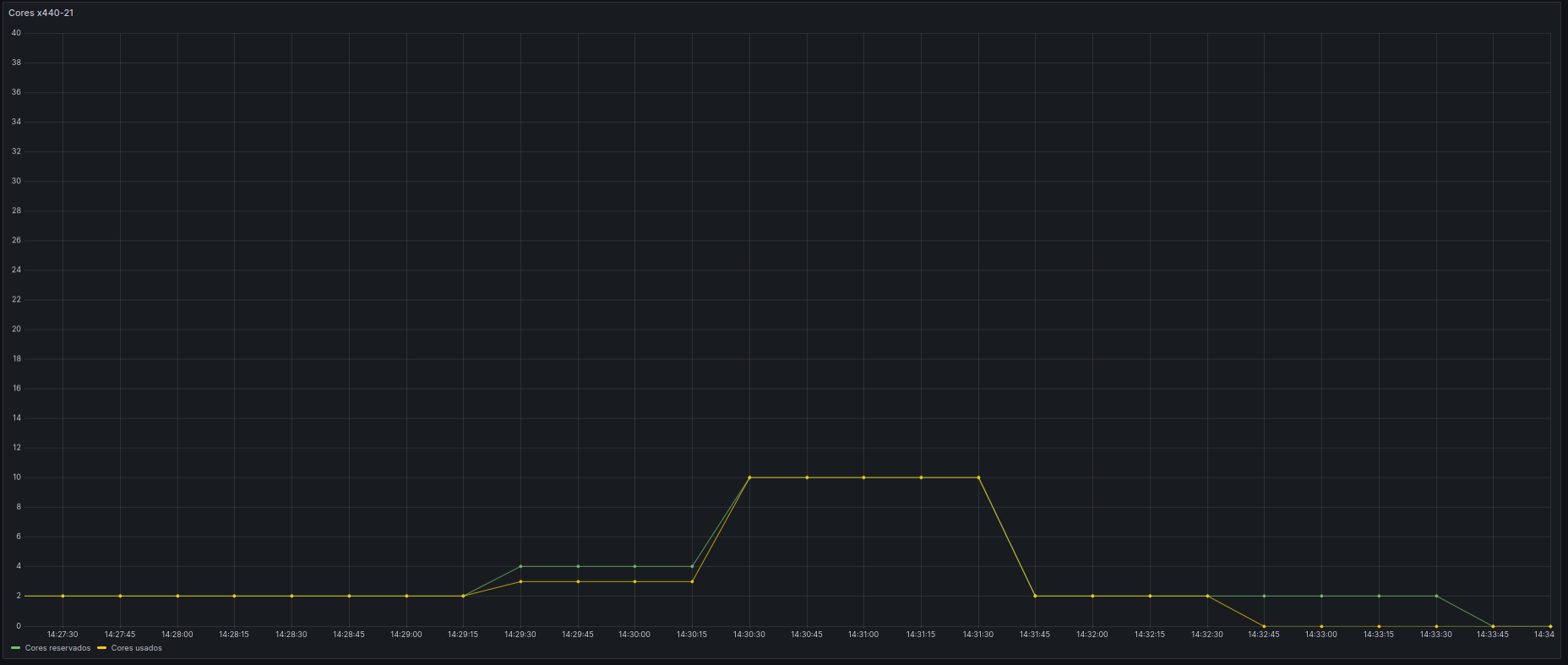
Frente a esto, se puede usar una estrategia de separar las tareas en un único trabajo usando diferentes especificaciones. Supongamos el siguiente shell script:
#!/bin/bash srun --job-name=adquisicion --mem=1G --partition=fast --cpus-per-task=10 stress --cpu 1 --timeout 120 srun --job-name=curado --mem=10G --partition=fast --cpus-per-task=2 stress --cpu 4 --timeout 60 srun --job-name=analisis --mem=4G --partition=fast --cpus-per-task=5 stress --cpu 10 --timeout 60 srun --job-name=resultados --mem=1G --partition=fast --cpus-per-task=5 stress --cpu 1 --timeout 120
#!/bin/bash #SBATCH --job-name=pipeline #SBATCH --cpus-per-task=10 #SBATCH --mem=10G #SBATCH --output=pipeline.log stress --cpu 1 --timeout 120 stress --cpu 4 --timeout 60 stress --cpu 10 --timeout 60 stress --cpu 1 --timeout 120
Attachments (2)
- pipeline-cpu.png (40.6 KB) - added by i22balur 13 months ago.
- steps-cpu.png (38.3 KB) - added by i22balur 13 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip