Opened 8 years ago
Last modified 8 years ago
#191 new defect
Caida de IOPS del Unity con un patrón horario determinado
| Reported by: | tonin | Owned by: | |
|---|---|---|---|
| Milestone: | SANUCO 3.0 | Component: | UNITY GENERAL |
| Version: | 1.0 | Severity: | major |
| Keywords: | iops rendimiento unity | Cc: | javier, cc0luism |
| Origen: | Parent ID: |
Description
Se observa una caida acusada de iops (casi el 50%) con un pico máximo a las xx:20 de cada hora.
Child Tickets
Attachments (12)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (18)
Changed 8 years ago by tonin
comment:1 Changed 8 years ago by tonin
Changed 8 years ago by tonin
Changed 8 years ago by tonin
Changed 8 years ago by tonin
Changed 8 years ago by tonin
Changed 8 years ago by tonin
comment:2 Changed 8 years ago by tonin
Respuesta de Ismael Martín de EMC
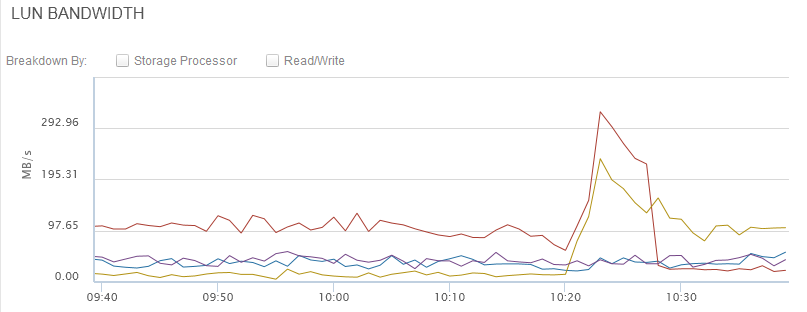
He estado mirándolo esta mañana. No me parece que esté relacionado con el CRON que comentas; he mirado en otras cabinas y tienen estos mismos comandos y las gráficas no se comportan de la misma manera. Además, he sacado los logs de rendimiento y veo que la bajada en realidad se da aproximadamente en los minutos 16, y entre los 40 y los 50 segundos:

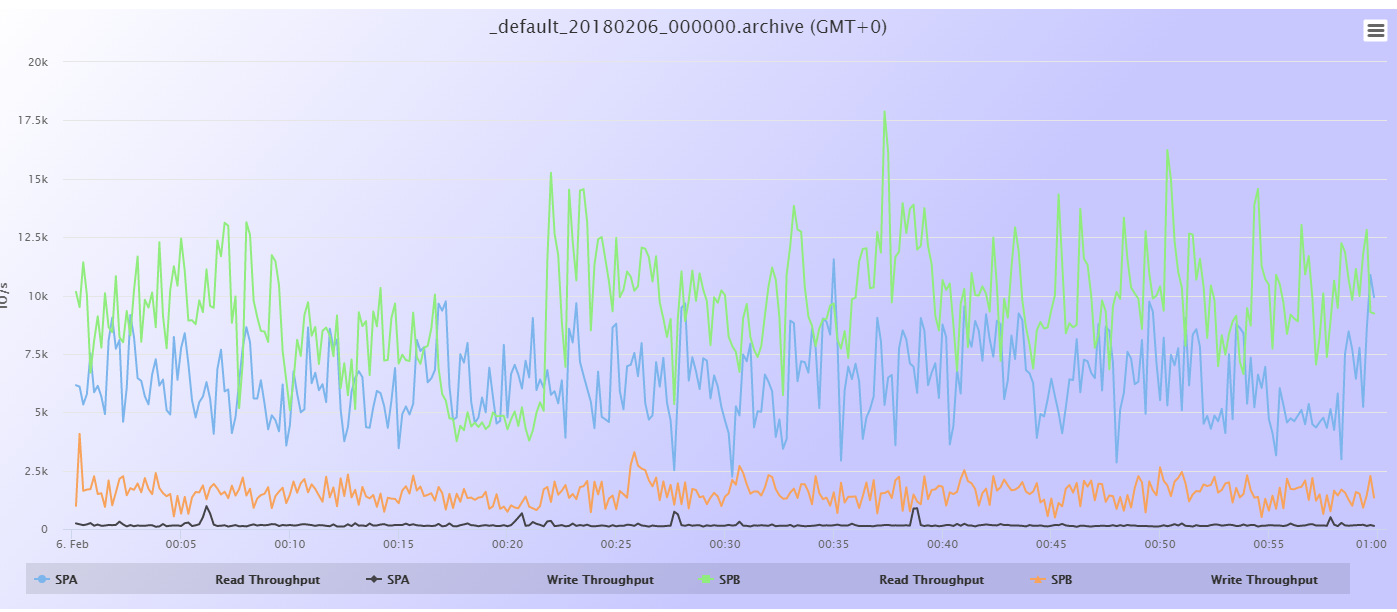
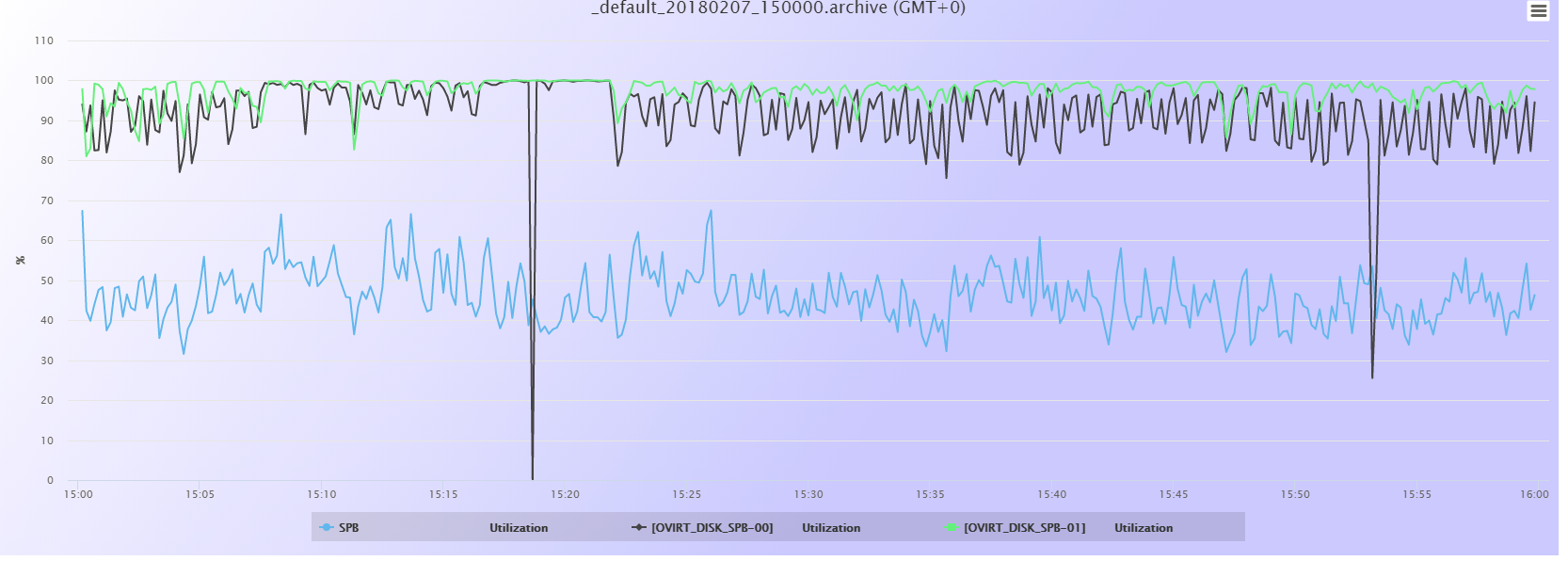
Lo que ya sabemos es que se trata de Throughput en lectura, en el SP B (que es el primario):

(es la gráfica verde, perdona que no se ve muy bien)
A la hora mencionada, entre los minutos 16:40 y 16:50, tampoco encuentro ningún proceso que solo se dé en ese momento. Todos los procesos que hay se repiten en otros momentos del día sin consecuencia en el rendimiento.
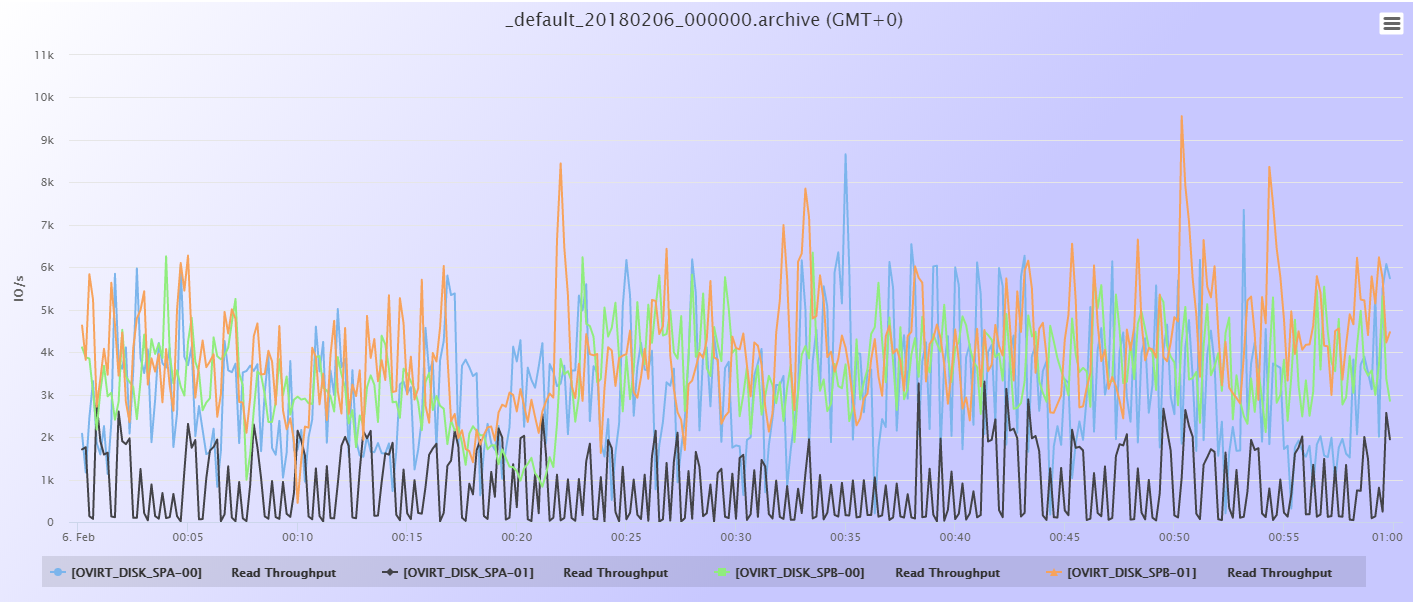
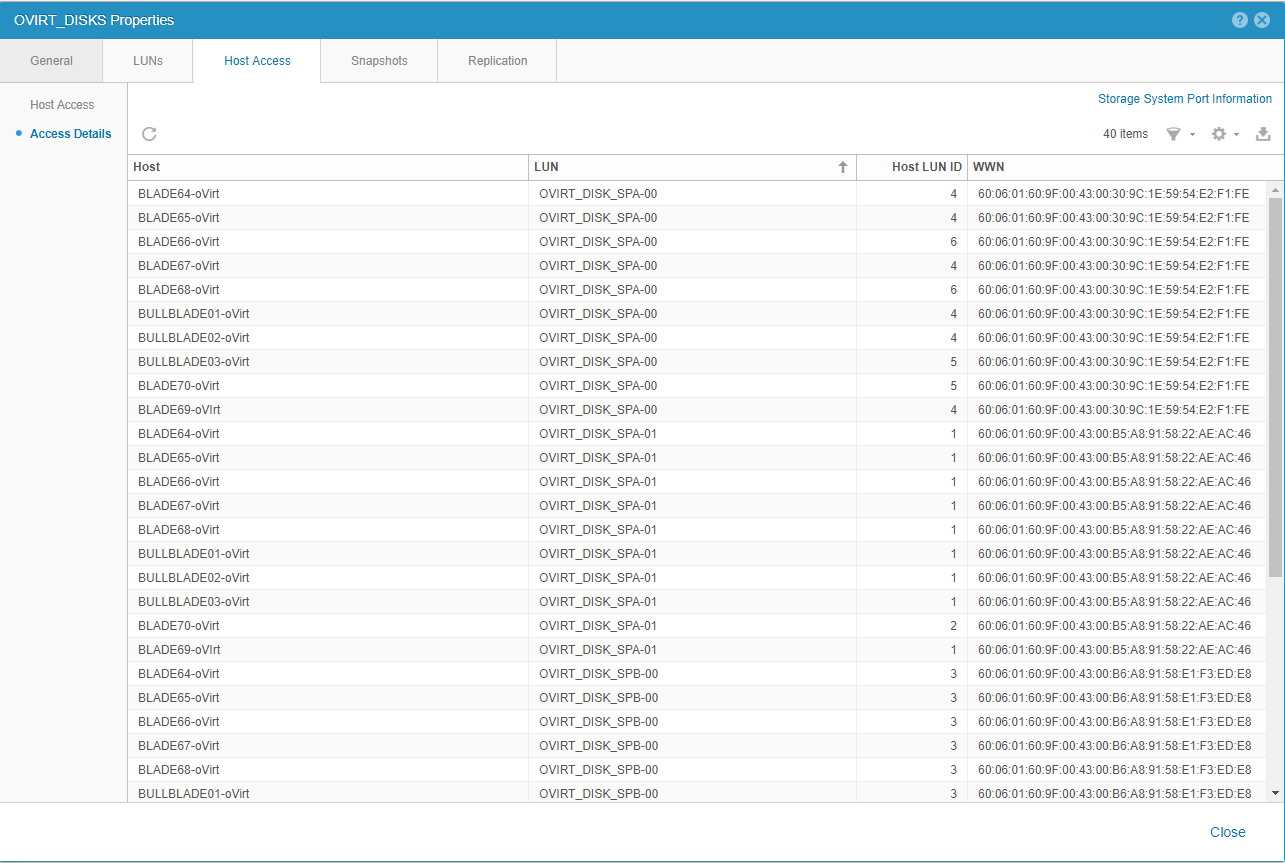
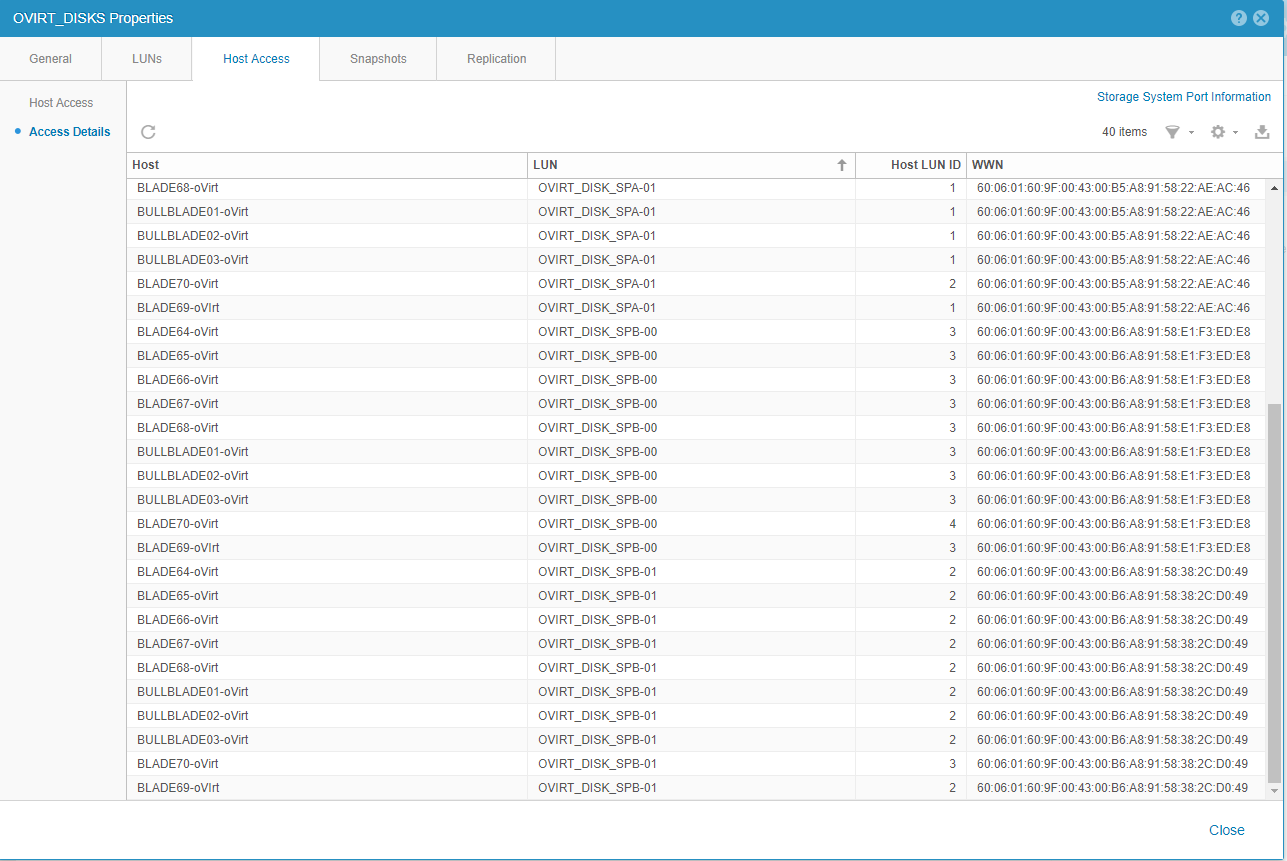
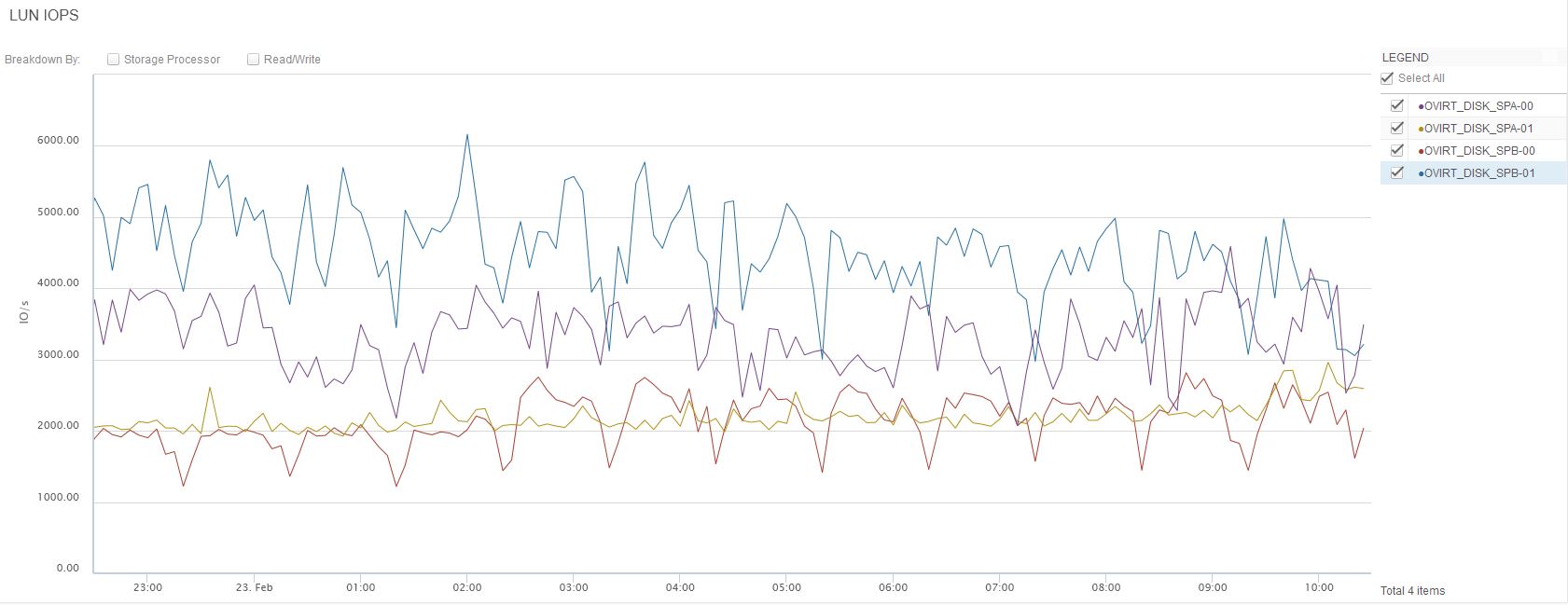
A nivel de LUNs, veo que la bajada de throughput de lectura se corresponde con bajada también de throughput en algunas LUNs, en especial OVIRT_DISK_SPB-00, y en menos medida en OVIRT_DISK_SPB-01 Y OVIRT_DISK_SPA-00. La única del Consistency Group OVIRT_DISKS que no tiene el mismo comportamiento es OVIRT_DISK_SPA-01.

Lo que me extraña un poco, en el Consistency Group OVIRT_DISKS, es que los Host LUN IDs no son los mismos para cada LUN y cada uno de los servidores que acceden a estas LUNs. La recomendación de rendimiento es que todos los servidores mantengan el mismo Host LUN ID para cada LUN; de esta manera, todos los host que acceden a la LUN OVIRT_DISK_SPA-00 tienen que tener configurado el Host LUN ID a 4; para la LUN OVIRT_DISK_SPA-01, el Host LUN ID a 1; OVIRT_DISK_SPB-00 a 3 y para OVIRT_DISK_SPB-01 a 2.
Ahora mismo, para la LUN OVIRT_DISK_SPA-00 hay varios servidores que tienen el Host LUN ID distinto a 4. Para el resto, el servidor BLADE70-oVirt es el que tiene los Host LUN IDs intercambiados:


No estoy achacando directamente el comportamiento del throughput a este problema de HLU, pero tampoco lo descartaría. Otras revisiones pasarían por comprobar si hay tareas programadas en las horas mencionadas en estos servidores.
El cambio de HLU se recomienda realizarlo en una ventana offline; incluyo el procedimiento para más información.
comment:3 Changed 8 years ago by tonin
Muchas gracias Ismael por en análisis. Efectivamente esta mañana mirando el tema con los compañeros también hemos visto que a las y veinte tenemos el pico de iowait y de bajada de iops, pero que comienza a producirse antes.
Es realmente extraño porque un aumento del iowait en un servidor puede producirse por un aumento de la demanda de iops de la cabina por parte de los servidores o por una bajada en la entrega de iops de la cabina. Si fuera el primer caso cabría esperar que el aumento del iowait correspondiera a una subida en las iops de la cabina que no se produce, por lo que parece ser lo segundo.
No parece que esta cabina full flash con menos de 12K iops en la primera gráfica que pones tenga problemas de saturación para bajar a menos de 7K, y esto de forma periódica cada hora. Sabemos que en contienda las gráficas pueden ser engañosas, pero no creo que los discos estén en contienda a esos niveles.
Vamos a seguir investigando nosotros a ver si podemos sacar algo más de información. Lo de los HID me lo tengo que releer detenidamente, pero me parece raro que un posible "problema" con eso se repitiera cada hora y siempre a la misma hora.
Changed 8 years ago by tonin
comment:4 Changed 8 years ago by tonin
La lun OVIRT_DISK_SPB-00 que nos indicas como "fluctuante" y causante de la bajada de IOPS horaria en una lun asignada a nuestra infraestructura de virtualización ovirt (RHEV), el equivalente a un vvol datastore de vmware en este caso usando lvm. Hay un montón de VMs que tienen su disco ahí.
Esta lun tiene la particularidad de que es el master del storage domain de ovirt, es donde ovirt almacena metadatos de los volúmenes de lvm que de todas formas se encuentran replicados en las otras 3 luns. Pensamos cambiar su papel de master a otra lun, pero esto no nos atrevemos a hacerlo en horas de carga y llegado el caso es una prueba que dejamos para más adelante.
Analizando las VMs que residen en esa lun pensamos en dos candidatas a ser miradas con lupa pues son VMs que no gestiona nuestro área de sistemas sino el área de comunicaciones y el de desarrollo, por lo que no las tenemos tan controladas como las nuestras.
Una de ellas se llama wifiman que es la que gestiona nuestra wifi y almacena estadísticas. Es una máquina que tradicionalmente nos ha dado problemas de carga de cpu. Por tanto lo primero que hemos hecho es migrar esta máquina del OVIRT_DISK_SPB_00 a OVIRT_DISK_SPA_01 que era la lun con menos IOPS. Aquí tienes una gráfica (la primera en rojo, la segunda en naranja)

El pico de ambas es producto de la migración, y cuando termina se intercambian los papeles ambas luns siendo ahora la OVIRT_DISK_SPA_01 la que carga más y bajando la OVIRT_DISK_SPB_00. Ahora tendremos que esperar unas horas para ver si el patrón de las "y veinte" se sigue repitiendo y en este caso por la caida de IOPS de OVIRT_DISK_SPA_00, o lo que sería lo mismo, por la caida de IOPS de la VM wifiman, que tiene toda la pinta. Te enviaré la gráfica esta tarde o mañana.
Suponiendo que se cumpla lo previsible tenemos tres preguntas:
1.- ¿La caida de IOPS se puede producir no porque haya una sobrecarga de uso de la cabina en el intervalo de caida sino porque wifiman en ese intervalo no demande IOPS mientras que el resto del tiempo si?
2.- Si lo anterior fuera cierto, ¿como se explicaría que una menor demanda de IOPS por parte de wifiman se tradujera en otras máquinas como nuestros servidores imap en un aumento del iowait precisamente en ese periodo?
3.- Llegado el caso de tener que analizar esa máquina por vuestra parte, supongo que harían falta emcgrab, pero en este caso al ser algo variable en el tiempo, ¿como se generan para que reflejen esta variación temporal?
Changed 8 years ago by tonin
Changed 8 years ago by tonin
comment:5 Changed 8 years ago by tonin
Respuesta de Ismael de EMC
Revisando las gráficas de rendimiento de ayer, el comportamiento del SP B es ahora el siguiente:

Sigue existiendo una caída en el throughput a esas horas, menos pronunciada que antes. Ahora mismo, la LUN que tiene un comportamiento más parecido que el del SP B es la LUN OVIRT_DISK_SPB-01.
Si nos fijamos en el porcentaje de utilización en ese momento, el SP B no está especialmente cargado, con lo que no diría que se trata de una sobrecarga del procesador en ese momento. Las dos LUNs OVIRT del SP B sí están bastante cargadas, mostrando valores cercanos al 100% antes y después:

El pico que baja al 0% es un falso positivo, no es real; en ocasiones las gráficas muestran bajadas o subidas inmediatas debido a que en algún calculo interno ha hecho alguna división por cero o algún valor que haya hecho disparar la gráfica; es un error de muestreo y no refleja el comportamiento real de la cabina. He tomado datos de otras horas diferentes y no aparece este pico.
Con los valores de utilización del procesador (entre el 40% y el 60%, aproximadamente) y los valores de utilización de las LUNs (al 100% aproximadamente), me inclinaría más por que fuera derivado de la utilización de estas LUNs.
En principio, si os viene bien, revisamos unos emcgrabs de al menos un par de servidores que accedan a estas LUNs. ¿Son ESX? Para saber qué ejecutable enviarte. En cuanto al rendimiento del servidor, hay herramientas que podemos utilizar (esxtop, en el caso de los ESX, por ejemplo); si no vemos nada raro en el emcgrab pediré a nuestro experto local de servidores que nos eche una mano.
Changed 8 years ago by tonin
Changed 8 years ago by tonin
Changed 8 years ago by tonin
comment:6 Changed 8 years ago by tonin
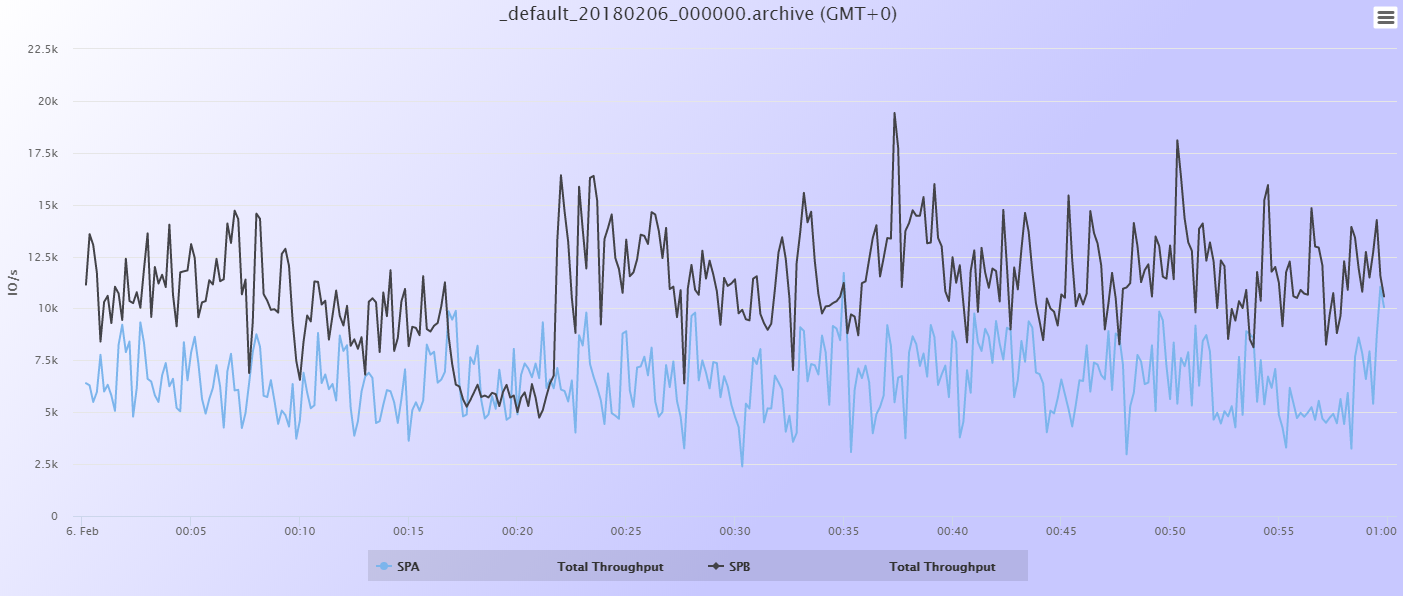
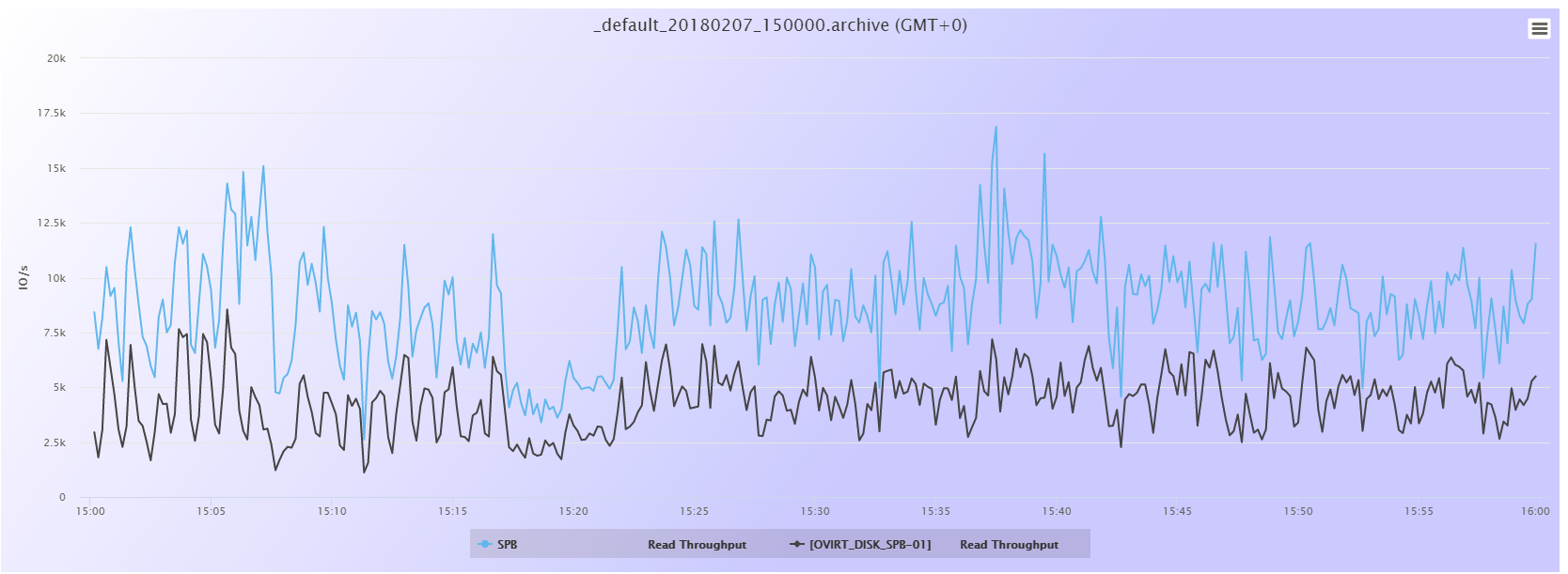
La situación en este momento tras la actualización de la infraestructura oVirt es la de la siguiente gráfica:

Y las máquinas alojadas en cada LUN son estas:

Un primer análisis de la gráfica nos indica lo siguiente:
- La única LUN que no presenta un patrón horario de caida identifcable es DISK_SPA_01
- El patrón es muy identificable y similar en ambas LUNs del SPB, DISK_SPB_00 y DISK_SPB_01
- DISK_SPA_00 coincide en muchos picos con los del SPB, pero en algunas horas o bien tiene el pico de caida desplazado o bien el pico no se presenta, como es el caso del periodo de ls 5:00 a 6:00
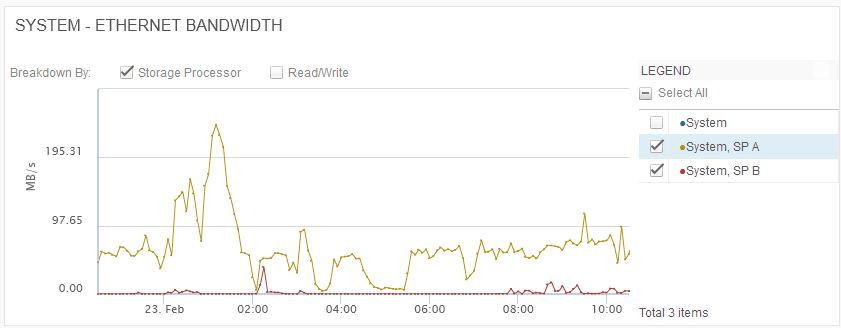
Como información adicional, nuestros NAS Servers se encuentran el de NFS en el SPA y el de CIFS en el SPB. En el periodo de la gráfica la proporción del tráfico ethernet entre NFS y CIFS es como mínimo de 5:1 llegando hasta 100:1 en algunos momentos:

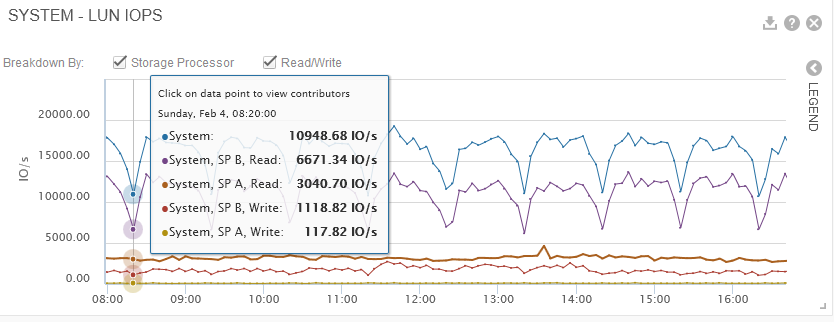
Monitorizando nuestros servidores hemos visto que exactamente a las y veinte de cada hora tenemos un pico importante de IOwait. Crece de forma rápida, llega al máximo y después cae el iowait de golpe.
En la cabina hemos visto esto:

Como se ve, cada hora y precisamente a las y veinte hay una caida de casi el 40-50% de iops, que parece ser la causa de nuestro aumento del iowait.
¿Puede ser que la cabina cada hora y precisamente a las y veinte se tome un "descanso" o haga algo que pueda provocar dicha caida?